雑文発散
2014-11-13 [長年日記]
▼ [Elasticsearch] そういえば Elasticsearch のバックアップ・リストアってどうなんだっけ?
昨日の「Elasticsearch で Web のクローリングを行なう」ってのは、だいたい動いているようなので、課題であった kuromoji のインストールをしようかと思ったのだが、そうするとマッピングの変更になって、今までのデータを一回消さないといけないはず。
マッピングの追加だけなら消さずともできるとかって記述をどこかで見かけた気がするのだけど、ちょっと忘れてしまった。調べ直さないといけないな。
まぁ、でも、今回は一度データを消して、再度クローリングをするようにしようと思ったものの、一旦ストアしたデータのバックアップってどうやればいいんだっけ?という疑問に答えられない自分がいたので、こちらはこちらで別途調べてみることにした。
公式のマニュアルだと「snapshot and restore」が該当っぽい。バックアップとは言わずに、スナップショットという用語を使っているようなので、この日記でも以降はスナップショットと表記する。
スナップショットの手順としてはこうなるのかな。
- スナップショットの定義
- スナップショットの取得の実行
- スナップショットの状態確認
ちょっとやってみよう。
スナップショットの定義
定義するのは、スナップショット取得のタイプとその保存場所になるようだ。
デフォルトで用意されているタイプは、fs と url みたい。fs は共有ストレージのことで、保存と(リストア時の)読み込みができる。url は読み込みのみ。
最初は、なんで「共有ストレージ」なの?と思ったけど、良く考えたら Elasticsearch は標準でクラスタ構築ができるので、そのデータは各サーバ(ノード)に分散保存されているのであった。
ノードが1台であれば、サーバ・ローカルのストレージに保存しても良いのだけど、複数サーバが絡んでくるなら、各サーバからアクセス可能な領域でないとダメだわなぁ。
つまり、こういうイメージになるわけだ。
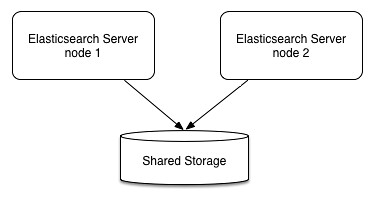
と、まぁ、概念は理解したものの、いまはサーバ1台で動かしているので、ローカルのファイルシステムへ保存する設定にしておく。
snapshot.json
設定用のファイル。スナップショットを保存する先を仮に /tmp/es_backup とした。もちろん、本稼働する際には /tmp は使っちゃいけないんだけど、まぁ、実験だし。
ちなみにスナップショットのファイルは、Elasticsearch の稼働ユーザ権限でファイルが作られるので、パーミッションはそういう感じにしておく必要がある。
{
"type": "fs",
"settings": {
"location": "/tmp/es_backup",
"compress": true
}
}
設定の投入
_snapshot というエンドポイント(API)へ backup という名称で設定を PUT してやる。
% curl -XPUT 'http://localhost:9200/_snapshot/backup' -d @snapshot.json
{"acknowledged":true}
設定内容の確認
現在のスナップショット設定を確認するには、_snapshot API を GET してやればいい。この辺りは、ドキュメントの追加とかと同じ考えなので分かりやすいよな。
% curl -XGET 'http://localhost:9200/_snapshot?pretty'
{
"backup" : {
"type" : "fs",
"settings" : {
"compress" : "true",
"location" : "/tmp/es_backup"
}
}
}
設定内容の削除
ここまで来れば想像通りに DELETE で設定を削除できる。
% curl -XDELETE 'http://localhost:9200/_snapshot/backup'
{"acknowledged":true}
スナップショット取得の実行
実行するには、設定名 backup にスナップショットの名前を付けて PUT してやる。ここでは snapshot_1 という名前にしている。
$ curl -XPUT 'http://localhost:9200/_snapshot/backup/snapshot_1?wait_for_completion=true'
wait_for_completion ってのは、その名前の通りで、終了するまで待つってフラグらしい。テスト時には付けておいた方が分かりやすそうだけど、本番稼働時にはバックグラウンドで動作させるのが良いよね。
あ、でも、終了を待って次の処理をする場合とかにはフォアグラウンド動作の方が楽か。その辺は要件次第だなぁ。
スナップショットの状態確認
取得したスナップショットがどうなっているのか?は GET で取得できる。
% curl -XGET 'http://localhost:9200/_snapshot/backup/snapshot_1?pretty'
この取得方法だと、クラスタに含まれる全てのインデックスが含まれているようだ。
スナップショットの削除
スナップショットの削除は予想通り DELETE で実行する。
% curl -XDELETE 'http://localhost:9200/_snapshot/backup/snapshot_1'
{"acknowledged":true}
特定のインデックスを指定してスナップショットを取る
インデックス webindex のみのスナップショットを取ってみる。スナップショットの取得時に indices を指定することで、インデックスを指定することができるようだ。
{
"indices": "webindex"
}
これを snapshot_webindex.json というファイル名で保存し、そのファイルを指定する形でスナップショット取得を実行する。今度は wait_for_completion=true を付けずにバックグラウンドで実行してみる。
% curl -XPUT 'http://localhost:9200/_snapshot/backup/snapshot_2' -d @snapshot_webindex.json
{"accepted":true}
コマンド投入後、すぐに accepted が返ってきた。
しばらく待った後、状態を確認してみる。
% curl -XGET 'http://localhost:9200/_snapshot/backup/snapshot_2?pretty'
出力はこうなった。
indices の部分が先ほどと違って、webindex のみになっている。期待通りの動き。
この時、スナップショットの取得先として指定したディレクトリはこのようなファイル構成になっていた。
% ls -alF /tmp/es_backup/
total 24
drwxrwxrwx 3 suzuki suzuki 4096 Nov 13 21:49 ./
drwxrwxrwt 9 root root 4096 Nov 13 21:56 ../
-rw-r--r-- 1 elasticsearch elasticsearch 31 Nov 13 21:49 index
drwxr-xr-x 17 elasticsearch elasticsearch 4096 Nov 13 09:03 indices/
-rw-r--r-- 1 elasticsearch elasticsearch 176 Nov 13 21:49 metadata-snapshot_2
-rw-r--r-- 1 elasticsearch elasticsearch 178 Nov 13 21:49 snapshot-snapshot_2
indices ディレクトリの中を見てみる。
% ls -alF /tmp/es_backup/indices/
total 68
drwxr-xr-x 17 elasticsearch elasticsearch 4096 Nov 13 09:03 ./
drwxrwxrwx 3 suzuki suzuki 4096 Nov 13 21:49 ../
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 kibana-int/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.03/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.04/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.05/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.06/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.07/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.08/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.09/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.10/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.11/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.12/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 logstash-2014.11.13/
drwxr-xr-x 3 elasticsearch elasticsearch 4096 Nov 13 21:48 _river/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:48 robot/
drwxr-xr-x 7 elasticsearch elasticsearch 4096 Nov 13 21:49 webindex/
あれ?複数のインデックスが入っているように見える。おかしいな?と思ったので、各ディレクトリの容量を見てみる。
% du -sh /tmp/es_backup/indices/*
24K /tmp/es_backup/indices/kibana-int
24K /tmp/es_backup/indices/logstash-2014.11.03
24K /tmp/es_backup/indices/logstash-2014.11.04
24K /tmp/es_backup/indices/logstash-2014.11.05
24K /tmp/es_backup/indices/logstash-2014.11.06
24K /tmp/es_backup/indices/logstash-2014.11.07
24K /tmp/es_backup/indices/logstash-2014.11.08
24K /tmp/es_backup/indices/logstash-2014.11.09
24K /tmp/es_backup/indices/logstash-2014.11.10
24K /tmp/es_backup/indices/logstash-2014.11.11
24K /tmp/es_backup/indices/logstash-2014.11.12
24K /tmp/es_backup/indices/logstash-2014.11.13
8.0K /tmp/es_backup/indices/_river
24K /tmp/es_backup/indices/robot
3.0M /tmp/es_backup/indices/webindex
webindex のディレクトリだけがそれっぽい容量になっているので意図通りになっていそうだ。よしよし。