雑文発散
2002-07-29 なにがなんだか月曜日
▼ うーむ
なんか今日の徒歩通勤は疲れた。いつもより歩くペースは落としていたんだけど。ちょっと土日の疲れが残っていたのかな?
▼ ランチ
会社を出たところで、半年くらい前までご近所さんで、今は別の場所に引越してしまったネットベンチャー系の方に会う。ひさびさにこの近くまで来たので、別のご近所さんと昼食を取る予定だと言うのでご一緒に。社長やら取締やら、僕以外はみんな役もち。おまけに僕以外は結婚していることも判明。ウチの取締役以外は僕より年下ばかりなのにね。
▼ 社長体質
確かに社長向きだと思うよ。人に仕事(?)を振るのとかうまいしね。僕は逆に人に振れずに自分で処理しようとしてしまう。で、自分でこなせているうちはいいけど、そのうち破綻してしまったり。。。もう少し人を使えるようになれば、僕も社長業に!、、、という考えにはならない。僕は表に出るよりも影で動く方が好きなので。よきゅんを社長に仕立てて、影の支配者として君臨する構図がいいなぁ。あ、資金は全くないので、誰か資本プリーズ(笑)
▼ 眠気が消える時間
この時間(17:54)になって眠気がやっと取れた。ここから今日の仕事スタートといった感じだなぁ。さて、あと数時間、がんばりますか。
2003-07-29 マッサージ行けなかったのが効いてきた、火曜日
▼ 光
職場に光が入った。引越時に導入のはずが遅れに遅れてやっと。これで回線が冗長化されたので、どっちかの回線なりプロバイダなりにトラブルが発生しても回避できる。
でも、停電になったらどうしようもないんだよなー。頼むぞ、東電!
▼ best / クラムボン
それどころじゃなーい!というトラブル対策の最中に届いた。処置が終わって開封したら、2枚組のうち1枚は DVD だってことが判明。そんなことも知らずに買ってたよ。。。
▼ Finder の高負荷
再起動したにも関わらず、まだ Finder の高負荷状態が続いている。CPU Usage が100%超えるときもあるし、特に何もしてないのに uptime 値が2とか出る。どーすりゃいいんだ、こりゃ。

2006-07-29
▼ [雑] 微妙に手帳が欲しいのよ
しばらく前からなんとなく手帳が欲しくなっていた。ただ、今までメモ帳を使ったことはあるものの、いわゆるシステム手帳は使ったことがないので、どんなのが良いのか分からず売り場で見ては「んー」と思って買わずにいた。
で、今日も良いのがないかなぁと思って立ち寄った伊東屋で、ひとつ良さそうなモノに出会った。それがKNOXの「包み込む手帳」だった。

製品コンセプトが「まるで一枚の布のように、電卓や携帯端末(PDA)、携帯などをざっくりとひとまとめにし、携行して、会議に臨む。そんな新感覚の手帳です」とあるのも気になった。
結局、今日は買うまでには至らなかったのだけれど、もうしばらくこの欲望を寝かせておいても変わらなかったら買ってみようかな。ホントに使うのかわからんのだけど。。。
あと、PDAと一緒に使ってる人の感想が知りたいなぁ。
2014-07-29
▼ [Emacs] Emacs Lisp の Info に日本語が表示されていた
php-completion.el をいじっていて、ちょっと(だいぶ?) Emacs Lisp の関数名とかが分からずにググったりしてたんだけど、「そもそも Emacs に Info があったっけな」と表示してみたら、ちょっと見慣れない表記が。
英語のマニュアルなのに「機能」の部分だけ日本語になってた。
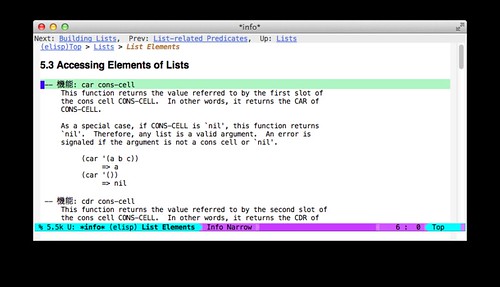
他にも「変数」「マクロ」「ユーザーオプション」という日本語表記も発見できた。
Info で表示されている実体のファイル /usr/local/Cellar/emacs/HEAD/share/info/emacs/elisp.info.gz の中身には日本語が含まれているので、表示しているときに置換しているわけでは無さそう。
Info ファイルの元となっている .texi ファイルだと、「機能」になっている部分は「@defun」というキーワード(?)になっていた。
つまり、Info ファイルを生成する時点で、日本語化が行なわれていたようだ。
これって、inline patch をあてたから?と思ったけど、なんか違う気がする(調べてない)。コンパイル環境の環境変数 LANG とか見てるのかな。それなら ja_JP.UTF-8 にしているので、なんとなく納得がいく。
2015-07-29
▼ [Elasticsearch] Elasticsearch 2.0.0 で導入予定の Pipeline Aggregations が便利そうなので自分なりにまとめてみたよ
先日の Elasticsearch 勉強会で Pipeline Aggregations のドキュメントを紹介されてから、数日ちまちまと眺めているのだけど、「これはもしかしてあればいいのになぁと思っていた機能なのでは!?」と思うようになって、ちょっとだけマジメにドキュメントを読み始めた。
実は以前に公開された 2.0.0 の紹介記事でも Pipeline Aggregations に触れられているんだけど、パフォーマンス改善やマイグレーションの話に目がいってしまって、「ふーん」とスルーしてしまっていた(せっかく書かれていたのに申し訳ない)。
改めてその記事を見直すと、Pipeline Aggregations の話が一番上に書いてある。一番上ってことは、一番訴求したい項目であって、一番ウリな機能ってことじゃないか!!!
ちょっと落ち着こう。
Pipeline Aggregations とは「Aggregation で集計された結果をさらに Aggregation できる」というのが超絶ざっくりした解説になる。
最初(というか単にアルファベット順)に説明されているのは、Avg Bucket Aggregation で、こいつが何をできるかというと、こういう表が Elasticsearch のクエリ一発で表せるようになるってことだよね、きっと。この「平均」の部分を Elasticsearch 側で計算してくれる。
| 月 | 売上数 | 売上額 |
|---|---|---|
| 2015-01 | 3 | 550 |
| 2015-02 | 2 | 60 |
| 2015-03 | 2 | 375 |
| 平均 | 328.33 |
縦方向の集計としては、「平均」の他に「最大」「最小」「合計」の計算が可能みたいだ。上の表で言えば、「平均」の部分の代わりに「最大の売上額」「最小の売上額」「売上額の合計」が簡単に出せそうだ。
こいつらを整理するとこんな体系になっている様子。「* Bucket Aggregation」という名前が一連のシリーズだと思えばいいのかな。
こういった「集計後のデータのさらに平均だとか合計だとか」を、Web アプリなどに表示したい場合ってどうしていただろう? わりと「データベースで集計した結果をアプリ側でさらに計算して平均(合計)を出す」ということをやっているのではないだろうか。少なくともオレはそうしている。
もちろん SQL をちょっとがんばれば、この表を一発で返すこともできるだろうけど、アプリでちょいちょいとやってしまった方が楽そうに思う場合が多いので。
でも、例えば Avg Bucket Aggregation のクエリはすごいシンプルに書ける。リファレンスから引用するとこんな感じ。
{
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"avg_monthly_sales": {
"avg_bucket": {
"buckets_paths": "sales_per_month>sales"
}
}
}
}
Avg Bucket Aggregation の本体は "avg_monthly_sales" 以下の JSON 部分になる。ちなみに "avg_monthly_sales" というのは、ラベルみたいなものなので好きな名前を付ければ良いところ。本当の本体は "avg_bucket" の部分で、これが「Avg Bucket Aggregation を使え」という指定。さらに "buckets_paths" が、前段の集計のどの結果を使うかの指定。上の例で言えば、「sales_per_month の中の sales という値」を対象にする、という意味になっているのだと思う。
「sales_per_month の中の」を表すのが「>」みたい。これは AGG_SEPARATOR と呼ばれるものらしい。詳細は buckets_path Syntax に書いてあるけど、まだあまり理解していない。
縦方向の集計をしていると、GROUP BY foo HAVING bar <= 50 みたいに集計結果の絞り込みが欲しくなるときがあるけど、それは Bucket Selector Aggregation で実現できるようになりそう。
つまり、次のような全体の集計があるとした場合を考えてみる。
| 月 | 売上数 | 売上額 |
|---|---|---|
| 2015-01 | 3 | 550 |
| 2015-02 | 2 | 60 |
| 2015-03 | 2 | 375 |
Bucket Selector Aggregation を使えば、次のように「売上が 200 未満の集計結果のみを表示」などができる。こういうの待ち望んでいた感じ、あるよね!!
| 月 | 売上数 | 売上額 |
|---|---|---|
| 2015-02 | 2 | 60 |
さて、縦方向の集計があれば、横方向の集計もあるわけで、Derivative Aggregation では変化量(差分)を集計することができる。つまりこのような表の「前月との差額」を一発で集計できるみたいだ。(あ、でも、こういうの、横方向の集計とは言わないかな。単に横に表を広げるのでそういう言い方をしてしまっている)
| 月 | 売上数 | 売上額 | 前月との差額 |
|---|---|---|---|
| 2015-01 | 3 | 550 | |
| 2015-02 | 2 | 60 | -490 |
| 2015-03 | 2 | 375 | 315 |
また、Cumulative Sum Aggregation では、このような「累積額」を一発集計できるやつっぽい。
| 月 | 売上数 | 売上額 | 累積額 |
|---|---|---|---|
| 2015-01 | 3 | 550 | 550 |
| 2015-02 | 2 | 60 | 610 |
| 2015-03 | 2 | 375 | 985 |
さらに Bucket Script Aggregation を使うと、もっと細かい横方向の拡張ができるようだ。
例えば、こういう表が一発で作れるみたい。「Tシャツが売上に占める割合」の部分を Bucket Script Aggregation で求めることができる。
| 月 | 総売上数 | Tシャツの売上数 | 総売上額 | Tシャツの売上額 | Tシャツが売上に占める割合 |
|---|---|---|---|---|---|
| 2015-01 | 3 | 2 | 50 | 10 | 20% |
| 2015-02 | 2 | 1 | 60 | 15 | 25% |
| 2015-03 | 2 | 1 | 40 | 20 | 50% |
この他にも Moving Average Aggregation や Serial Differencing Aggregation が Pipeline Aggregations に含まれている。それぞれ、だいたい何をやっているのかは把握できたものの、うまく説明する自信がないので、いまは置いておく。時系列データを分析する場合には使えそうな予感だけはしている。
Elastic 社 CTO の Shay さんが「Elasticsearch は検索がスタートだったけど、集計にも使われることが増えてきたので、そちらにも力を入れ始めている」というような発言をされていた(と思う)んだけど、それはこういうことだったんだなぁと思った。
そしてこういう用途への拡張を意識して「PostgreSQL のようにデータの信頼性を維持できる Elasticsearch にしていきたい」という発言に繋がったのだなぁなどと思ったりもした。
あ、ちなみにここに書いたものは、全てドキュメントから把握してまとめたもの。本当は実際に HEAD の ELasticsearch を動かしつつ試してみようとか思っていたんだけど、なんか手元でビルドがうまくいかずにまだ試せていない。間違っていたところがあったらごめんね。
▽ mostbet_ikPa [Народ кто ставит Вечно то лаги Нервов потратил — мама не г..]
▽ Mitchelintok [В Новороссийске круглосуточная наркологическая служба рабо..]